
1 创建项目
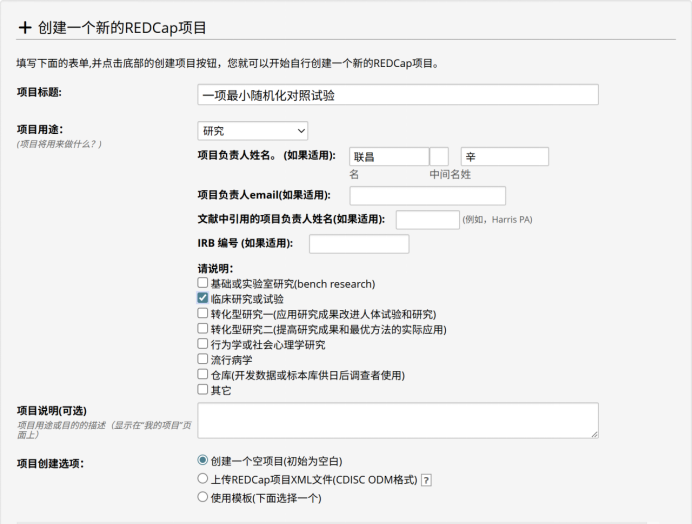
图 1 REDCap中建立项目的页面
登录REDCap系统,在项目仪表板点击“创建一个新的REDCap项目”,填写项目全称,用途类型选择“临床研究或试验”,如图1。
2 构建病例报告表(CRF)
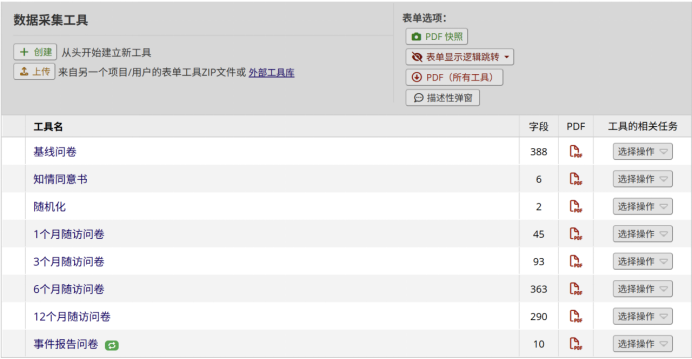
图 2 “在线设计”中创建的CRF表
进入左侧菜单“在线设计”,依次创建以下字段:记录标识符(record_id);人口学资料:年龄分层(单选按钮:<55岁/≥55岁)、性别(单选按钮:男/女)、BMI分层(单选按钮:<30 kg/m²/≥30 kg/m²);其他临床数据字段(诊断、基线生命体征、随访等)。同时,在添加以上字段时选择合适的字段类型(单选按钮、文本框、下拉菜单等),如图2。
3 创建随机化专用字段

图 3 CRF表中创建的随机化信息
在CRF中新建一个独立的单选按钮字段,字段变量名建议设为randomization_group,标签可命名为“随机分组”,选项设置为“对照组”与“干预组”(图3)。该字段专门用于存储系统写入的分配结果,不应与其他数据录入字段混用。
若试验需要实施盲法,可改为文本字段存储无意义的随机编号,真实组别信息仅存储于系统后台,受试者与评估人员在CRF中仅能看到编号,直至研究结束揭盲。
4 激活随机化模块与配置用户权限
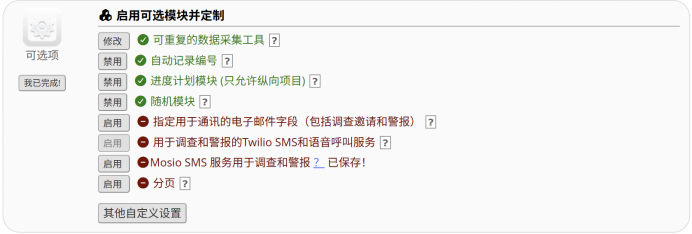
图 4 开启随机模块
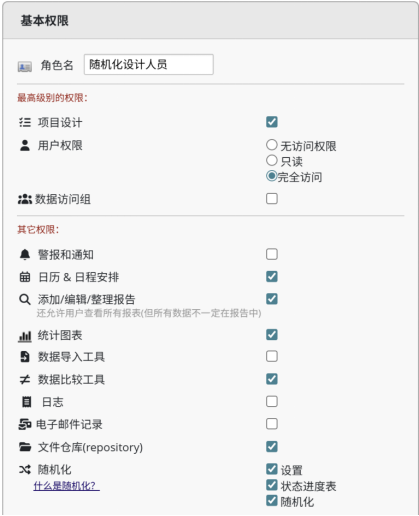
图 5 开启随机化设计人员的权限
在REDCap平台中,系统为确保随机化操作的安全规范,精细化各分层的权限管理。首先需要在项目设计层面激活相应的随机化功能模块,继而在用户角色层面分配具体的操作权限,以上两层权限相辅相成,缺一不可。
首先,操作人员须确保“随机模块”这一核心功能在项目设置中处于被激活状态。这一模块的开启决定了随机化工具是否对项目内的任何用户可用。其具体配置路径位于项目左侧导航菜单的“项目设置”中的“启用可选模块并定制”区域。在此区域内,找到“随机模块”,其状态初始为“禁用”。为开启随机化试验,操作人员须点击“禁用”按钮,将状态变更为“启用”,字体显示为绿色即说明已开启该模块。
随机模块启用后,建议创建名为“随机化设计人员”的专用角色。使其专为负责配置和执行随机化的核心研究人员(如项目负责人或生物统计学家)所设。其权限需在“用户权限”模块中进行定义,重点使左侧“随机化”对应的“设置”、“状态进度表”与“随机化”处于开启状态,以确保“随机化设计人员”后续可设置随机化、生成和下载状态进度表以及完成随机化,如图5。
5 配置最小随机化外部模块
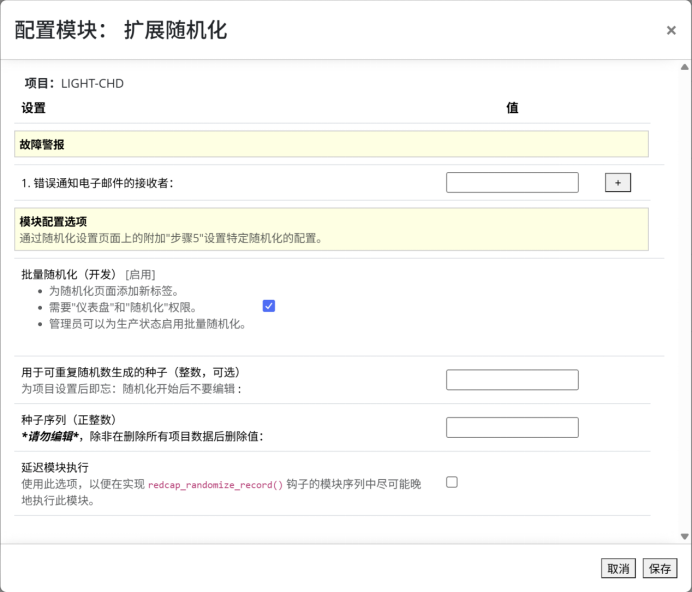
图 6 配置外部模块页面
在左侧菜单进入“外部模块→管理”,找到“Extended Randomization–v1.1.0”,点击“配置”进入配置界面(图6),填写以下参数:
(1)通知邮箱:填写研究负责人邮箱,系统在随机化过程出现异常时将自动发送告警通知;
(2)随机数生成种子(Seed for reproducible random number generation):建议使用研究方案伦理批准日期(格式如20241021)。该参数一经设定,在试验运行期间不应更改,以保障算法的可重复性与可审计性。
6 随机化模型设置
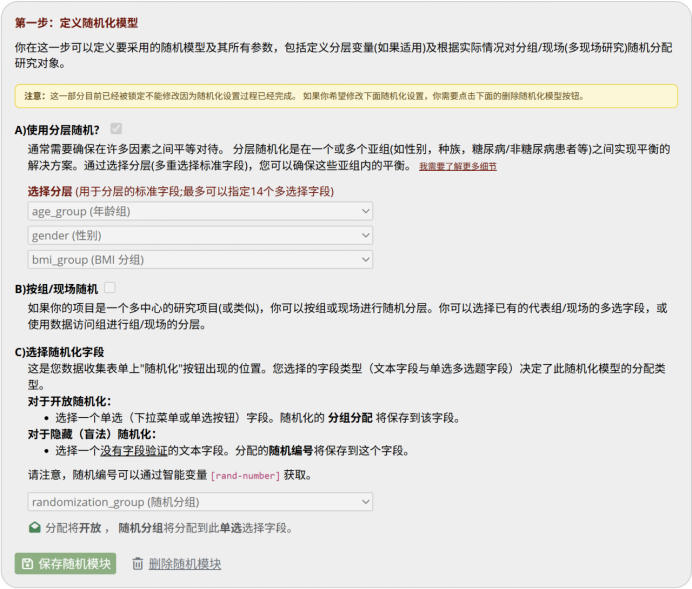
图 7 定义随机化模型的页面
进入左侧菜单“随机化”,点击“添加新的随机化模型”,按以下步骤完成核心模型配置(图7):
步骤一:分层因素定义
选择“A) 使用分层随机”,勾选参与最小化计算的协变量字段:年龄分层、性别、BMI分层。此步骤相当于向系统声明“需要同时保护哪些变量的组间平衡”。
步骤二:分配结果字段指定
在“C) 选择随机化字段”中选择前述randomization_group字段,系统执行随机化后将自动将分配结果写入该字段,完成数据流的闭环。
7 分组表的下载与上传
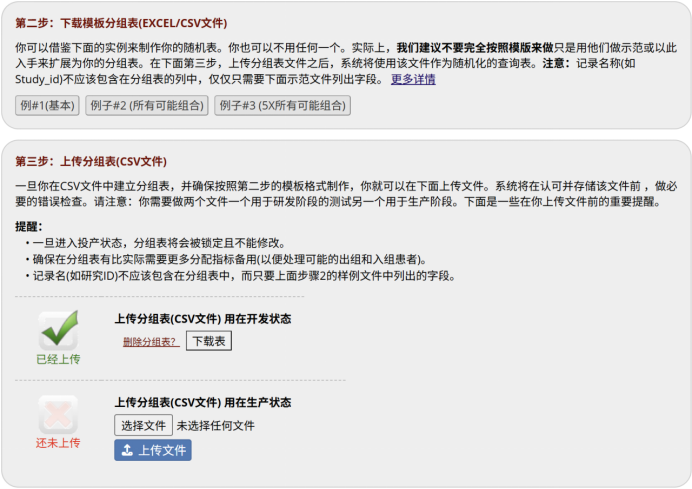
图 8 分组表的下载与上传页面
在随机化模型设置界面,点击“下载模板分组表”,选择“例子 #2(所有可能组合)”下载模板(图8)。下载后逐行核查文件中的组合是否覆盖试验中可能出现的全部协变量组合,确认无误后保存为CSV格式。在项目处于开发(Development)状态下完成上传与测试验证;全面测试通过后,再将项目切换至生产(Production)状态并正式上传,以保障生产环境数据的安全性。
8 偏向硬币最小化参数配置
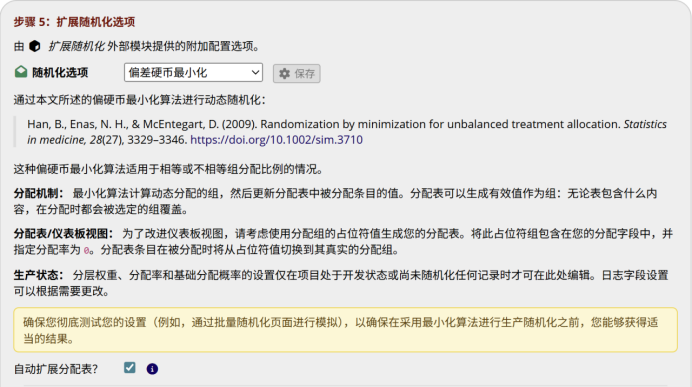
图 9 选择最小随机化算法
9 设置组别分配比例
在“分组分配比率”部分,为每个研究组别指定分配比例。本研究采用经典的1:1随机化分配方案。REDCap系统将以此比例为目标,通过最小化算法进行动态调整,确保两组受试者数量保持均衡。此外,该部分同样支持非均衡分配(如2:1),研究人员可按试验的需求在此处输入相应比例即可,这也体现了算法的灵活性。

图 10 设置组别分配比例页面
10 定义分层因素权重
在“分层加权”部分,为每一个在第一步中定义的分层因素指定一个权重。如图9所示,本文赋予年龄、性别、BMI三个因素以相同权重,意味着算法在权衡组间平衡时,会给予这三个因素同等的考量。所有权重之和为1。同样,此设置可根据临床实验所需,将临床专业知识量化融入最小随机化过程。例如,某项试验认为年龄的影响更大,可以为其分配更高的权重(如0.5),“偏硬币最小化算法”则会优先保证年龄因素的组间平衡,如图11。

图 11 定义分层因素权重页面
11 设定基础分配概率
在“基础分配概率”字段中,系统通常会给出默认值。本研究将此值设置为0.7,意味着当系统通过计算,认为将受试者分入A组更能平衡基线特征时,有70%的概率会将其分配至A组,同时保留30%的概率将其随机分配至B组。30%概率的随机成分确保了分配序列的不可预测性,严格维护了受试者分配的隐蔽性,防止了由于分配模式可被猜测而可能引入的选择偏倚。故此参数是平衡“最优化”与“随机性”的关键杠杆,该数值定义了当“偏硬币最小化算法”计算出一个“优选”组别时,实际将受试者分配至该组的概率。
编辑:冉竹逸,辛联昌;审校:米白冰
 陕公网安备61011302000964号
陕公网安备61011302000964号 扫码关注公众号
扫码关注公众号